一、TLD算法简介
TLD(Tracking-Learning-Detection)是英国萨里大学的一个捷克籍博士生ZdenekKalal在2012年7月提出的一种新的单目标长时间跟踪算法。该算法与传统跟踪算法的显著区别在于将传统的跟踪算法和传统的检测算法相结合来解决被跟踪目标在被跟踪过程中发生的形变、部分遮挡等问题。同时,通过一种改进的在线学习机制不断更新跟踪模块的“显著特征点”和检测模块的目标模型及相关参数,从而使得跟踪效果更加稳定、鲁棒、可靠。
二、TLD framework
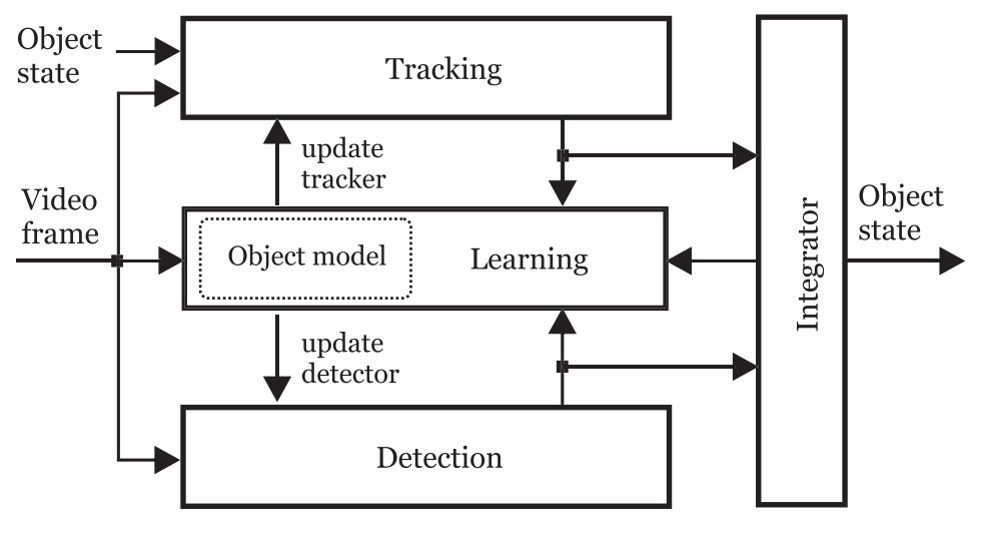
TLD是一个用于针对视频中未知物体长期跟踪的架构。简单来说,TLD算法由三部分组成:跟踪模块、检测模块、学习模块。跟踪模块是观察帧与帧之间的目标的动向。检测模块是把每张图看成独立的,然后去定位。学习模块将根据跟踪模块的结果对检测模块的错误进行评估,生成训练样本来对检测模块的目标模型进行更新,避免以后出现类似错误。
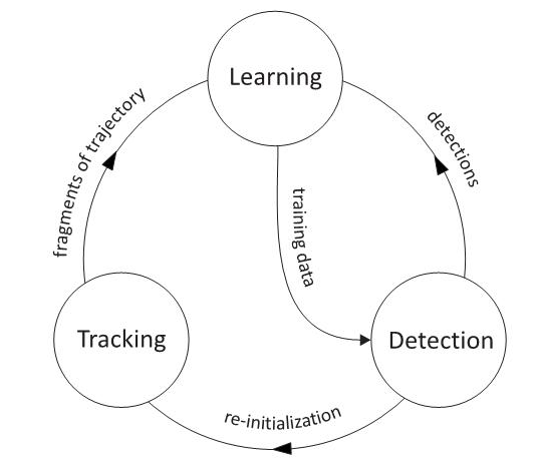
TLD跟踪系统最大的特点就在于能对锁定的目标进行不断的学习,以获取目标最新的外观特征,从而及时完善跟踪,以达到最佳的状态。也就是说,开始时只提供一帧静止的目标图像,但随着目标的不断运动,系统能持续不断地进行探测,获知目标在角度、距离、景深等方面的改变,并实时识别,经过一段时间的学习之后,目标就再也无法躲过。
TLD技术采用跟踪和检测相结合的策略,是一种自适应的、可靠的跟踪技术。TLD技术中,跟踪器和检测器并行运行,二者所产生的结果都参与学习过程,学习后的模型又反作用于跟踪器和检测器,对其进行实时更新,从而保证了即使在目标外观发生变化的情况下,也能够被持续跟踪。
三、TLD算法实现
1. detector 检测器的实现
检测器包括三个:一是方差检测器;二是随机深林;三是最近邻分类器;
step1 首先,输入一幅图,人工指定目标矩形框,然后通过在整幅图上进行扫面窗口得到一堆图像patch。
扫描窗口的实现:设定了21个尺度,在选定的目标矩形框大小基础上,向上梯度10个,向下梯度10个。尺度梯度为1.2,每个梯度下都进行窗口扫描,步进为窗口大小(宽度和高度都是10%)的10%,获取按照设定的扫描方式扫描得到整幅图像的patch。当然大小也有限制,最小窗口尺寸为15x15。
step 2 从patch中得到用于训练和测试的随机深林和最近邻分类器的样本。
选择的标准是从patch与目标矩形框的重叠度overleap,重叠度越大,越认为是正样本,重叠度越小就认为是负样本。具体的正样本和负样本见下图:
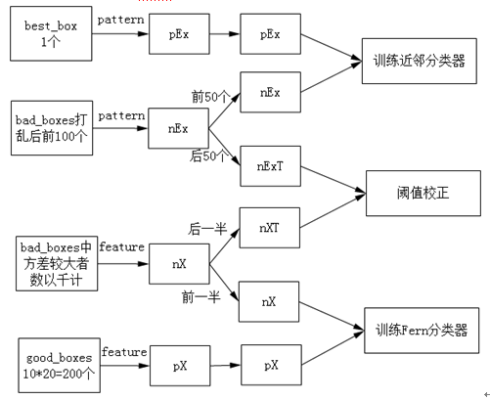
对于最近邻分类器,正样本只有一个就是best_box,即我们认为选定的或者是TLD输出的上一帧最好的结果。
step 3 方差分类器
利用平方积分图IIimage和积分图Iimage可快速计算任意patch的方差:var(patch) = IIimage(patch)- Iimage(patch)x Iimage(patch)。方差小于best_box的方差50%的patch就直接淘汰。只有通过方差分类器的才能进入随机森林
step 4 随机深林的训练和测试

这是随机深林的训练过程和测试过程:随机深林的大小为10棵树,树的大小为13个节点,每个节点都是一个基于像素比较的decisionstump。Decisionstump就是一个阈值切割,大于则为1,小于则为0;
Decisionstump的构造是随机的选取输入patch中的两点位置上的像素值进行比较,每棵树之间的decisionstump选取的点是随机的,同一颗树上的decisionstump也是随机的,所以称之为随机深林。但是,在随机深林初始化后,forest的结构也就固定了,每次通过随机深林时所对应的node节点上的decision stump是固定的,即每一帧上对应的同一棵树上的同一个节点所代表的像素比较点的位置是固定的,因此才能进行后验概率的学习。
首先是将通过方差检测的图像patch,分别输入10棵树上,树的每个节点上进行一个特征的decisionstump切割,最后每棵树的输出为一个13位的二进制编码.
利用采集到的正样本和负样本对decisiontree的输出二进制值的后验概率进行学习:P(y|X)=pN/(pN+nN),有了这个我们就可以进行决策:10棵树的P之和与设定的阈值相比较就可以进行决策。而学习的过程就类似一个perception,犯错了才进P值的调整(犯了漏检则增加pN,犯了误检则增加nN)。
| y | 0 | 0 | …… | 0.7 | 1 |
| X | 0 | 1 | …… | 2^13-2 | 2^13-1 |
比如,输入的样本为(X,1),但是却小于阈值,被判定为负样本,则说明对应的P太小,需要提高,因此对P(1|X)进行增大。
测试过程:
利用测试集输入到训练好的随机深林中进行测试,主要是用来调整阈值。测试集都是负样本,从而统计负样本在随机深林上的得分,取得分最高的作为阈值。(这样所有的负样本基本上是不可能通过随机深林的)
step 5 最近邻分类器的训练和测试
最近邻分类器实际上就是在线的模板匹配,将输入的图像patch,通过仿射变换转变为15*15的patch,并进行0均值化,然后与在线的正样本模板和负样本模板进行匹配,计算对应的相关相似度和保守相似度。
最近邻分类器训练
最近邻分类器的训练过程其实就是更新在线模板的过程,如果输入的patch为正样本,但与在线的正、负模板pEx、nEx的相关相似度小于阈值,则分类错误,就将该输入的patch放入在线正模板pEx中。如果输入的patch为负样本,但与在线的正、负样本相关相似度大于阈值,则分类错误,就将该输入的patch放入负样本模板nEx中。效果就是动态地更新了在线模板
最近邻分类器测试
最近邻分类器的测试过程实际上跟随机深林的测试过程一样,为了调增对应的阈值,测试集全部是负样本,选取负样本中得到相关相似度最高的值作为最近邻分类器的分类阈值。
2. 中值流跟踪器的实现
TLD算法的跟踪模块(Tracker),是一种在名为中值流跟踪(Median-Flow tracker)的跟踪方法基础上增加了跟踪失败检测算法的新的跟踪方法。中值流跟踪方法利用目标框来表示被跟踪目标,并在连续的相邻视频帧之间估计目标的运动。
在TLD算法中,原作者将10*10的格子中的像素点作为初始特征点,并利用金字塔LK光流法来在连续的相邻视频帧之间估计若干特征点的运动。
跟踪模块的跟踪失败检测算法:
中值流跟踪算法的前提假设是目标是可见的,所以当目标完全被遮挡或者消失于视野,则不可避免地出现跟踪失败。为了能够解决这些问题,我们采用如下策略:
让di表示其中某一个点的移动位移, dm表示位移中值,则残差可定义为 |di-dm|。如果残差大于10个像素,那么就认为跟踪失败。这个策略能够很稳定地就确定出由剧烈移动或者遮挡所造成的跟踪失败。
获取points1和points2的10x10亚像素精度区域,并进行像素匹配,得到匹配度作为相似度的衡量。通过计算points1和FB_points之间的距离,并归一化,作为错误匹配度的衡量。
剔除50%相似度小的和50%错误匹配度大的特征点
3. 综合器的实现
综合器(Integrator)把检测器和跟踪器得到的目标框予以综合,并作为TLD最后的输出。如果跟踪器或者检测器都没有得到目标框,那么就认定当前帧中被跟踪目标没有出现的,否则,综合器将具有 最大保守相似度的图像片作为最终的目标框所在位置。
1)先通过 重叠度 对检测器检测到的目标boundingbox进行聚类,每个类的重叠度小于0.5:clusterConf(dbb,dconf, cbb, cconf);(2)再找到与跟踪器跟踪到的box距离比较远的类(检测器检测到的box),而且它的相关相似度比跟踪器的要大:记录满足上述条件,也就是可信度比较高的目标box的个数:if(bbOverlap(tbb, cbb[i])<0.5 && cconf[i]>tconf)confident_detections++;(3)判断如果只有一个满足上述条件的box,那么就用这个目标box来重新初始化跟踪器(也就是用检测器的结果去纠正跟踪器):if(confident_detections==1) bbnext=cbb[didx];(4)如果满足上述条件的box不只一个,那么就找到检测器检测到的box与跟踪器预测到的box距离很近(重叠度大于0.7)的所以box,对其坐标和大小进行累加:if(bbOverlap(tbb,dbb[i])>0.7)cx += dbb[i].x;……(5)对与跟踪器预测到的box距离很近的box和跟踪器本身预测到的box进行坐标与大小的平均作为最终的目标boundingbox,但是跟踪器的权值较大:bbnext.x= cvRound((float)(10*tbb.x+cx)/(float)(10+close_detections));……(6)另外,如果跟踪器没有跟踪到目标,但是检测器检测到了一些可能的目标box,那么同样对其进行聚类,但只是简单的将聚类的cbb[0]作为新的跟踪目标box
4. 学习模块的实现
Learning实际上就是重新组织正负样本对随机森林和最近邻分类器进行训练。训练的方式跟上面讲解的一样。
什么时候重新组织训练呢?实际上只对有跟踪结果参与的目标输出进行训练。
对新得到的当前帧的TLD目标输出box进行最近邻的检测,得到与在线模型的正负模板的相关相似度,如果相关相似度比较小,或者方差比较小,或者已经在在线模型中了,就不用训练学习了。否则就在该输出的位置进行类似初始化时候的训练一样,随机深林的后验概率和最近邻分类器的在线模板进行更新。当然就没有了像初始训练中的将数据集拆分为训练集和测试集的过程了。